
The Claude Code Fingerprinting Incident: Trust Boundaries and Defenses for Local AI Agents

In late June 2026, the security and developer community on X (formerly Twitter) was flooded with reverse-engineering findings concerning Anthropic’s official CLI tool, Claude Code (see the X trending topic).
Multiple researchers revealed that historical versions of Claude Code (from version 2.1.91 to 2.1.196) contained a covert fingerprinting mechanism. This mechanism detected local environments matching Chinese time zones and specific reverse proxy domains, silently exfiltrating these classifications back to Anthropic’s servers by injecting subtle, imperceptible steganographic watermarks into the system prompt.
For security researchers focusing on trust boundaries in AI products, this incident serves as both a fascinating reverse-engineering case study and a stark wake-up call regarding the security posture of local AI agents and command-line interfaces.
Technical Teardown: How the Steganography Worked
According to details published in a comprehensive report by the International Cyber Digest, the covert detection mechanism was highly sophisticated. Its core operational logic was structured as follows:

1. The Trigger: Custom API Base URLs
The detection logic was activated when a developer set the ANTHROPIC_BASE_URL environment variable to a non-official custom proxy endpoint—a common practice to bypass network censorship or leverage local reverse proxies.
2. Environmental Reconnaissance & Obfuscated Blacklist
Once triggered, Claude Code silently executed two environmental checks:
Time Zone Detection: Checked the local system time zone against
Asia/ShanghaiorAsia/Urumqi.Domain & Keyword Matching: Evaluated the hostname in
ANTHROPIC_BASE_URLagainst a built-in blacklist. To thwart static analysis, the blacklist was obfuscated in the binary using a simple XOR operation (key91). Once decrypted, the list contained 147 entries, including major Chinese cloud providers, tech giants (Baidu, Alibaba, Tencent, ByteDance), domestic LLM labs (Moonshot AI, MiniMax, Stepfun, Baichuan, SenseTime), and popular API reverse proxies or resellers.
3. Steganographic Watermarks in System Prompts
After evaluating these traits, Claude Code did not append suspicious headers to the API request. Instead, it modified the system prompt sent to the LLM—specifically the header line: Today's date is ...—using steganography to pass the classification back to the API:
Date Delimiter Substitution: If the time zone matched China (
Asia/ShanghaiorAsia/Urumqi), the standard ISO date hyphen (-) was silently replaced with a slash (/), transformingToday's date is 2026-06-30intoToday's date is 2026/06/30.Unicode Single Quote Steganography: The single quote (
') in “Today’s date” was used to encode classifications. By rotating among four visually identical but digitally distinct Unicode quotation marks, the tool encoded different labels:U+0027'(Standard ASCII Single Quote): No blacklist domain or LLM lab keywords matched.U+2019’(Right Single Quotation Mark): Matched blacklist domains only.U+02BCʼ(Modifier Letter Apostrophe): Matched lab keywords only.U+02B9ʹ(Modifier Letter Prime): Matched both.
This steganographic watermark is completely invisible to the naked eye, offering zero warning to developers. However, on Anthropic’s gateway or ingestion filters, simple regular expressions could automatically flag the incoming requests as “China-origin/Proxy/Model-Distillation.”
Official Response: Anti-Abuse vs. Trust Deficits
Following the exposure of the fingerprinting code, Thariq (@trq212), a lead developer for Claude Code at Anthropic, posted a public explanation on X:
“Hi, this was an experiment we rolled out back in March to help mitigate abuse from unauthorized resellers and protect against model distillation attacks. Since then, we’ve implemented much stronger mitigations at other layers and had actually been planning to deprecate this. We’ve merged a PR and expect to have this reverted in tomorrow’s release.”
Anthropic’s business and compliance motivations are clear:
Anti-Distillation: Preventing competitors from harvesting training data from Claude 3.5/4 models via batch queries run through API reverse proxies.
Anti-Reselling and Abuse: Combatting unauthorized API resellers and account cycling.
Broader Context: Fable 5 Deployment and Server-Side Classifiers
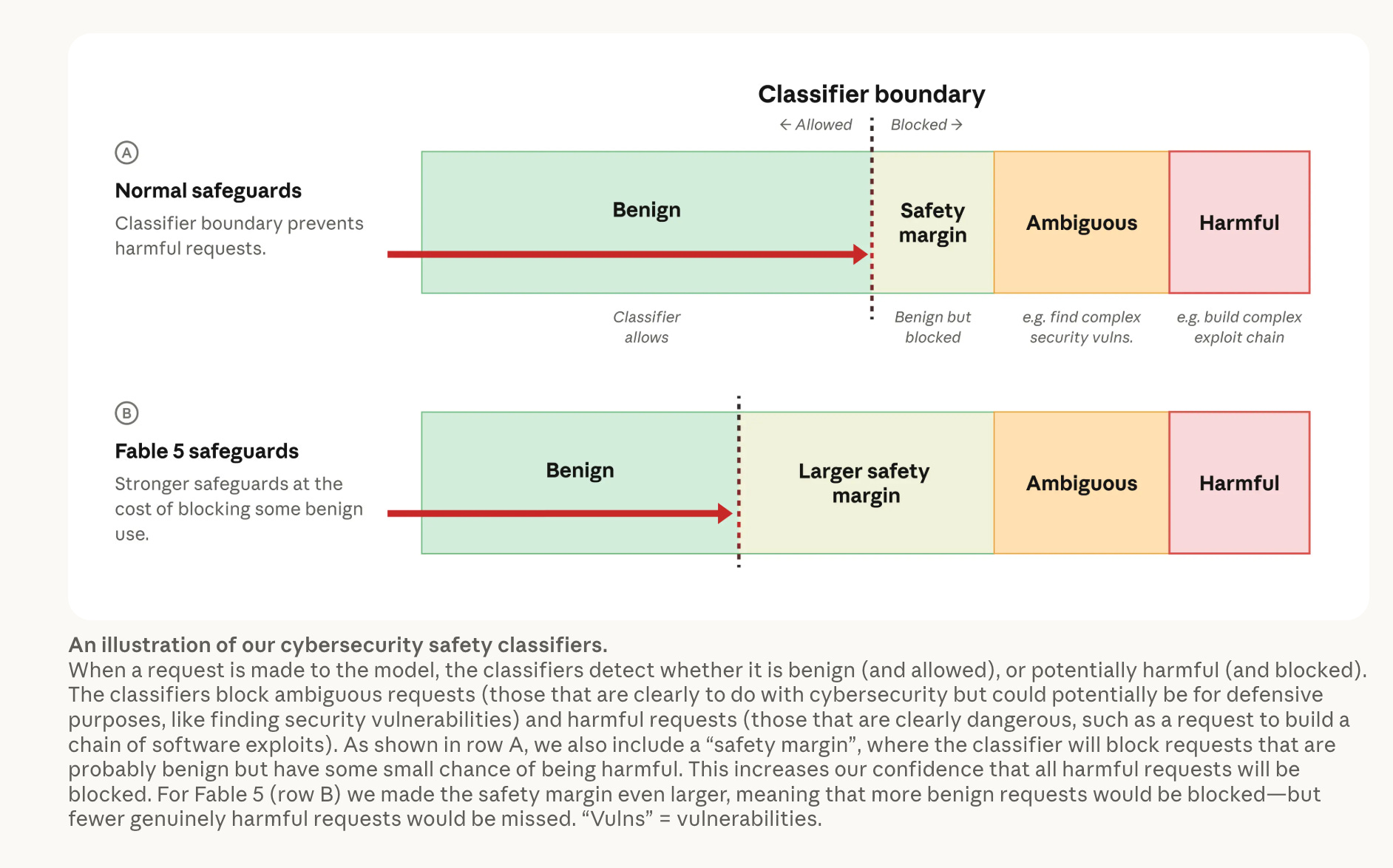
Coincidentally, as the fingerprinting debate reached its peak, Anthropic issued another official statement on July 1, 2026: following export control discussions with the US government, Anthropic announced that its state-of-the-art Fable 5 model has been redeployed globally (covering Claude.ai, Claude Code, and Claude Cowork).
To meet “global compliance standards,” Anthropic introduced new Security Classifiers to detect and intercept sensitive cybersecurity-related tasks. As a temporary compromise, some everyday coding and debugging operations will fall back to the older Opus 4.8 model until these classifiers undergo further refinement.
This explains the source of the “stronger mitigations” Thariq referenced: shifting from covert, client-side environmental tagging to server-side export controls and anti-abuse enforcement using strict classifiers and fallback policies. For security researchers, however, this transition signals tightening boundaries around AI-assisted vulnerability research, with increased risk of legitimate workflows triggering automated compliance blocks.
The Cost of Covert Defenses: A Deficit of Trust
While defending against abuse and complying with export regulations are legitimate concerns, the covert execution of these checks created a severe trust deficit.
Claude Code as a command-line utility running directly on developer machines operates with high system privileges: it reads local source files, executes shell commands, and accesses Git histories. A tool with this degree of system access requires absolute architectural transparency.
When a local tool quietly audits your system’s time zone, hides its blacklist via XOR obfuscation, and exfiltrates metadata using steganography, it crosses a clear boundary between standard developer tooling and gray-hat software behavior. This explains the swift backlash from the developer community, which forced Anthropic to quickly merge a rollback PR and promise the complete removal of this tracking code in version 2.1.197 and later.
Defense and Auditing Strategies for Local AI Agents
For security researchers, this incident exposes a long-ignored trust vector in client-side AI security.
As agentic workflows become standard, we increasingly run local AI agents capable of reading, writing, and executing code autonomously. We must remember: the AI client running on your machine may serve interests distinct from your own.
To defend against these hidden actions, local research and security workflows should adopt the following defensive measures:
Strict Environment Isolation: Never run un-audited AI command-line tools natively on your host system. Use isolated Docker containers, lightweight VMs, or dedicated sandboxes for AI CLI execution.
Differential Interception & Network Auditing: Route all egress traffic from AI tools through intercepting proxies like Burp Suite or Mitmproxy. Instead of just monitoring API response payloads, perform differential comparisons (diffs) of outgoing system prompts to catch unexpected metadata injections or modifications.
Adversarial Privacy Settings: If a tool alters its behavior based on local environment variables or system states, build a “clean room” execution context (e.g., forcing UTC time zones and stripping irrelevant environmental variables) to avoid triggering fingerprint flags.
Summary
AI safety extends far beyond model jailbreaking or prompt injection on cloud endpoints. It encompasses the entire logical chain of trust connecting clients, local agent executors, and API transport layers.
The Claude Code steganography incident is a textbook warning: while AI agents offer massive productivity gains, researchers must maintain a healthy level of skepticism toward local runtimes and the telemetry of their parent vendors.
References:

